2024年
2023年振り返り
去年の目標はインプットでした
機械学習
ChatGPTなどのLLMがかなり盛り上がった年だった。 LLMの流れがかなり速いのでインプットは追いついていない。 論文も少しは読んだけど、そこまで数は多くなかった。 それでもアウトプットは色々あり、動画要約などに関わったり、なぜかスポンサーの記者会見で話したり、参議院議員会館で話したりと不思議な経験が多かった。
- グノシーでGPT-3を活用した「動画AI要約記事」開発 2月24日よりβ版を提供決定 ユーザーと価値ある動画コンテンツとのマッチング機会を最適化|株式会社Gunosy(グノシー)|情報を世界中の人に最適に届ける
- 女子プロゴルファーの西村優菜プロとGunosyがスポンサー契約締結~発信力支援&データ分析支援でプレーをサポート~ -
- 新経済連盟主催 国会議員向け「最先端ビジネスセミナー」登壇レポート -
マネジメント
マネジメントとか、組織、チーム運営、キャリアなどの本を色々読んだ。まだアウトプットに結びつけられているかは怪しいけど
- 急成長を導くマネージャーの型 ~地位・権力が通用しない時代の“イーブン”なマネジメント
- スタッフエンジニア マネジメントを超えるリーダーシップ
- Scaling Teams 開発チーム 組織と人の成長戦略 (Compass Booksシリーズ)
- HARD THINGS 答えがない難問と困難にきみはどう立ち向かうか
- Who You Are(フーユーアー)君の真の言葉と行動こそが困難を生き抜くチームをつくる
- ブリッツスケーリング
- 自分の小さな「箱」から脱出する方法~人間関係のパターンを変えれば、うまくいく!
- エンジニアのためのマネジメントキャリアパス ―テックリードからCTOまでマネジメントスキル向上ガイド
- 本当の勇気は「弱さ」を認めること
- 米海軍で屈指の潜水艦艦長による「最強組織」の作り方
- 1兆ドルコーチ――シリコンバレーのレジェンド ビル・キャンベルの成功の教え
- エンジニアのためのマネジメント入門
マネジメントとは違うけど、課題解決関連の本も読んで、解像度を上げるという本は面白かった。
2024年目標
- 行動範囲を広げる
- ある程度固定化してきているので、活動範囲やら視野やらを広げたい
- 5年後について考える
- プレイヤー、マネージャーの両方を経験したので、経験を踏まえて今後どうしていくかを考えたい
2023年
去年の振り返り
去年の目標はアウトプットとチャレンジでした。
前半は本の感想書いたり、読んだ論文の実装を手元で試したりと、自分にしてはまぁまぁアウトプットできていたんだけど、5月あたりから仕事でバタバタしてそれ以降はアウトプット全くできなくなっていた。 10月からポジションも少し変わり、その少し前から関わる範囲も増えていき、色々キャッチアップしていたらいつの間にか年末に。締め切り案件もあり余裕がなかった。立場が少し変わったこともあり視野を広げるという意味ではチャンレンジは多少できたのかもしれない。
2023年
今年はインプットを改めて強化したい。 アウトプットしたり、勉強会に参加したりもできるとよいけど。
- 機械学習
- マネジメント
- マネジメントや経営などの知識、知見をもう少し学びたい
プロダクト関連の本を読んだ
Hidden Technical Debt in Machine Learning Systems にも書かれているように、システム全体に対して、機械学習のコンポーネントはほんの一部という話はよく言われるようになってきたと思う。 同様に、プロダクトに対して、機械学習を使った機能も(重要ではあるが)一部でしかないので、もう少しプロダクト全体について学んだ方が良いかなと思い、プロダクトマネジメントとかその周辺の本を読んでみた。
とりあえず、以下の本を読んでみた。プロダクトというより組織っぽい話も多かったけど、気になったところをメモ。
- プロダクト・レッド・オーガニゼーション
- プロダクト・レッド・グロース
- プロダクトマネジメントの全て
プロダクト・レッド・オーガニゼーション

セールス主導型組織とは異なり、プロダクトを主軸においたプロダクト主導型組織になるためのガイド本。
- オンボーディング体験
- プロダクトを使ってもらうにはオンボーディングが重要
- ユーザーがプロダクトの明確な価値を認識し、長期的な関わりを始めるポイントを「アハ・モーメント」と呼んでいる
- slackの場合、1チームで2000通のメッセージを送信したあたりらしい
- オンボーディング設計におけるアドバイス
- プロダクトではなく、ユーザーに焦点を当てる
- ユーザーを価値あるものへと早く導く
- ペルソナによるセグメント化
- 進捗ゼロという状態を作らない
- 長期の顧客維持状況の計測
- カスタマーヘルススコアを構築して計測
- Rapid7チームの例だと
- 短期: プロダクトの定着状況、サポート体験、購買行動
- 中期: カスタマーサクセスマネージャーからの情報、カスタマーマネージャーによるやりとり、NPS
- 長期: ITエコシステム、セキュリティ成熟度、プロダクト認証
- プロダクトの成功は機能の定着に依存
- 機能定着率など機能に関する計測をする
プロダクト・レッド・グロース

プロダクト主導型組織の成長戦略であるプロダクト・レッド・グロースについて書かれた本。オンボーディングの話が多くあっておもしろかった。
- プロダクト・レッド・グロースとは、ユーザー獲得、アクティベーション、リテンションをプロダクトそのものが担うという手法
- プロダクト・レッド・グロースを取り入れるということは、事業に関わる全てのチームがプロダクトに影響を与える
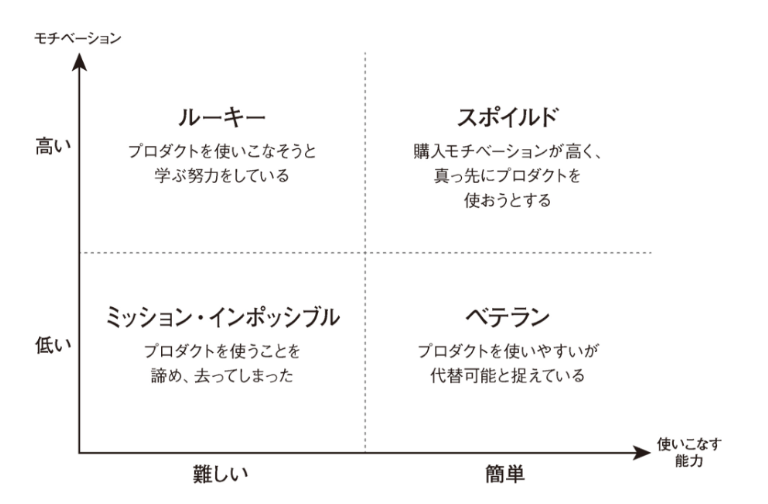
- ユーザーの4タイプ
- ミッション・インポッシブル、ルーキー、ベテラン、スポイルド
- スポイルドユーザーを増やせると良い
- コアユーザーと解約ユーザーの利用パターンを比べることで、バリューメトリクスをみつける
- プログレスバー
- すでに一部完了していると、完了させようとするモチベーションが上がるというのがおもしろかった
効果的なプログレスバーは最初から一部完了した状態にしてある。まったくゼロから始めるのではなく、すでに途中まで済んでいると感じさせることで、早く最後まで完了させたいという欲求を高められる。
- すでに一部完了していると、完了させようとするモチベーションが上がるというのがおもしろかった
- ツールチップ
- これもついやってしまいそうなことだけど、注意しないといけなそうだなと思った
- オンボーディング・ツールチップは、ユーザーが有意義な価値を得るために必要な手順を案内するために使おう。
- 人々がソフトウェアを使うのは、暇だからでも、ボタンをクリックして回るのが楽しいからでもない。
- これもついやってしまいそうなことだけど、注意しないといけなそうだなと思った
- 価格帯を改善することで、ARPUが20%改善した
- 不必要に設定された価格帯は取り除く
- 人は選択肢が多いほど、選択をしない可能性が高くなる
- バリー・シュワルツ氏が提唱した「選択のパラドックス」
- プライシングのオプションを3つ以下に抑える
- チャーンの種類
- カスタマーチャーン: 一定期間中に失ったユーザー数
- レベニューチャーン: 一定期間中に失った売上額
- アクティビティチャーン: 解約リストがあるとされるユーザー数
プロダクトマネジメントのすべて

プロダクトマネージャーのやることや必要なスキルについて広く浅く書かれた本。全体を広く知れて、個人的には読みやすかった。
- プロダクトの4階層としてCore, Why, What, Howを決める
- 上から順番に決めるわけではなく、上から下へ、下から上へと行ったり来たりしながらブラッシュアップする
- リーンキャンバスとのも書いてあってわかりやすかった
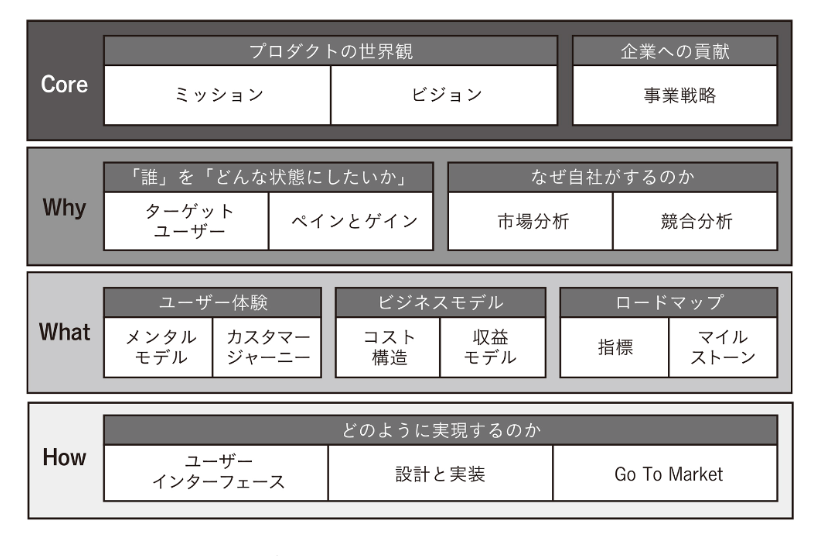
- プロダクトの大切なものランキング
- プロダクトの品質について
とりあえず広く浅くで読んでみたので、次はもう少し深ぼってみてもいいかなと感じた。
SVMs with Problem Context Aware Pipeline を試した
社内でやっているGunosyDMという論文読み会で少し前に Enhancing SVMs with Problem Context Aware Pipeline という論文を読んだ。シンプルで分かりやすかったので少し手元のデータを使って実験してみた。
論文について
論文の概要としては
- DNNは計算コストが高い。一方、 SVMは計算コストは低いが、複雑なタスクだと性能が悪い
- タスクを分解し複数のSVMを使うことで、複雑な問題も扱えるようになる
- パラメータなどを自動で学習することで、DNNと競える性能を出した
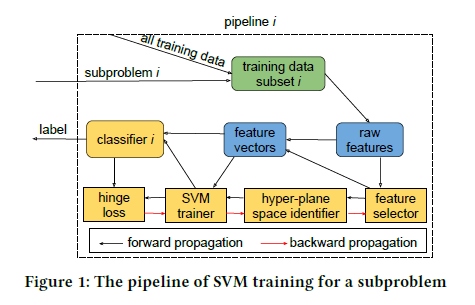
アプローチの概要としては
- データを特徴量を利用してkmeansなどでk個のデータに分割する
- 分割したデータそれぞれに対してSVM分類器を学習し、k個のSVM分類器を生成する
- 分割するとデータが不均衡になりやすいので、データ拡張で均衡になるようにする
- 特徴量選定なども分類器ごとに行う
- 推論時はk個のデータの重心ベクトルと比較し、どのSVM分類器で判定するかを決め、そのSVM分類器で推論する
もう少し詳しい説明は scrapbox のほうに書いている。
scrapbox.io
実験
コードも公開されていたので、手元にあるタスクに適用してみた。試したのは去年の言語処理学会に出した扇情的な記事判定タスク。
扇情的な記事判定に向けた定義作成とアノテーション
data.gunosy.io
SVM with Problem Context Aware Pipelineのコードは以下においてある。論文では、Aspects Based Sentiment Analysisという感情分析のタスクを解いている。
- https://github.com/Kurt-Liuhf/absa-svm
- https://github.com/Kurt-Liuhf/absa-svm/blob/master/whole_pipeline.py
whole_pipeline.py ではデータをk分割して、k個のSVMで学習・推論している。論文だとハイパラのチューニングやFeature Selectionもやっているが、whole_pipeline.py ではやっていない。論文のメインはデータ(タスク)を分解してそれぞれに問題を解くところにあるので、whole_pipeline.py でも十分そうな気がしたので今回はこれを使って試した。
結果としては以下のようになって、そこまで性能向上は見られなかった。Task2のほうが難しいタスクというのもあり性能の向上が多少見れた。データと特徴量をNLPの論文のときと少し変えているので、NLPの論文よりベースの性能がやや低い。学習データが1,300件程度しかないため、そもそも分割するほどデータ量がなく、元論文だと10分割しているが、このデータだと3分割が限界だった。元論文でもデータ数が少ないと効果が低いので、もっとデータ量や特徴量を多くするか、もう少しタスク分解が明確なタスクじゃないと効果は低いのかもしれない。
| Task | 判定するラベル | Model | Precision | Recall | F1-score |
| Task1 | SEXUAL, VULGAR | SVM | 0.905 | 0.779 | 0.837 |
| SVM with PCAP | 0.883 | 0.779 | 0.828 | ||
| Task2 | OFFENSIVE, CLICKBAIT | SVM | 0.780 | 0.271 | 0.403 |
| SVM with PCAP | 0.800 | 0.305 | 0.442 |
実験コードを公開してくれているとサクっと試せるのでありがたい。あと、DeepじゃなくてSVMというのもあり、試すのも楽だった。
失敗の科学を読んだ
年末年始にいくつか本を読んでいたが、失敗の科学という本が面白かった。

内容的には、失敗をしたときにきちんとその失敗から学びましょうというものだが、実際に大きな失敗をすると人や組織はその失敗を隠してしまったり、失敗を仕方ないものとして学ぼうとしない傾向があり、その現象をクローズドループ現象と呼んでいる。
航空業界ではオープンループがうまく回っているが、医療業界はクローズドループになってしまっていることや、心理療法士はフィードバックをきちんともらえないから経験が当てにならないなどが書いてあって面白かった。
おもしろかった点をいくつかあげておく
- 努力が判断を鈍らせる
- 努力や労力をかけているほど、失敗したときにその失敗を受け入れることが難しく、解釈を変えて失敗したことを無かったことにしてしまう
- 進んで失敗する
- 仮説検証の際に、正しそうなルールばかりを検証するのではなく、あえて失敗しそうなルールでも検証することも大事
- これはすごく大事だなと感じた。仕事で分析をするとき、最初に仮説を立ててから分析を始めることが多いけど、どうしてもその仮説が正しいことを示すデータを探しがちな気がする。その仮説に反する分析もしなくちゃなと思った。あと、よくよく考えると統計的検定は帰無仮説を棄却しているのでまさにこの考えなんだなと思った。
- ボトムアップ式の試行錯誤の重要性
- 技術の実用化は「研究 + 科学理論 -> 新たなテクノロジー -> 実用化」というトップダウン式の流れと考えられがちだが、実際にはボトムアップ式の試行錯誤から実用化され、理論はあとからということも多い
- これはまさにDeep Learningとかがその流れだなと感じる。
- スケアード・ストレートプログラム
- 非行少年と刑務所に訪問させ怖い思いをさせることで更生させようとする施策。実際には効果はなく、逆に悪化させていた。こういうストーリー性のあるものに惑わされやすい。
- 何かのテレビ番組でこのプログラムの話を見た覚えがあって、調べたらいくつかやってるみたいだった。テレビではいかにも更生しましたという感じで放送されていたので、本を読んで効果がないことを知って少し驚いた。
- 脳は一番「直感的」な結論を出す
- 脳は一番単純で一番直感的な結論をだす傾向がある。航空事故の調査官は10件中9件は「操縦士のミス」だと考えるらしい。
- 自分にとって都合が良い、単純な結論を出しやすいのはそうだなと感じるので、気をつけたいなと思う。
失敗から学ぶという当たり前に思えそうなことでも実際にはなかなか難しいんだなと思った。
仕事でも気をつけてないといけないことが学べておもしろかった。
今日でブログ開設から10年らしい。あんまり記事は書いてないけど。


2017年振り返り
2017年を振り返る。
- 手を動かす、行動する
- 自己投資
- そんなにできなかった気がするけど、東京に引っ越すタイミングで色々買い替えたので、まあいいかな
- 次の5年
- ビジネス、プロダクトへの貢献に対して、自分ができる/したいことを考えて、動けた1年だったかなと思う。
今年はなんといっても転職が一番大きな出来事だった。年始あたりから考えつつ、いくつか話を聞かせてもらいにいったりもして、最終的に今の会社にさせてもらった。転職後でまだまだインプットが多い状態だけど、今のところ、自分なりには良い選択だったんじゃないかなと思ってる。まあ、あとは自分次第。
今年は決断した1年だったけど、今年の決断が良かったかどうかがわかるのは来年以降なので、また来年がんばろう。あとはせっかく東京にきたので、東京を楽しみたい。