SVMs with Problem Context Aware Pipeline を試した
社内でやっているGunosyDMという論文読み会で少し前に Enhancing SVMs with Problem Context Aware Pipeline という論文を読んだ。シンプルで分かりやすかったので少し手元のデータを使って実験してみた。
論文について
論文の概要としては
- DNNは計算コストが高い。一方、 SVMは計算コストは低いが、複雑なタスクだと性能が悪い
- タスクを分解し複数のSVMを使うことで、複雑な問題も扱えるようになる
- パラメータなどを自動で学習することで、DNNと競える性能を出した
アプローチの概要としては
- データを特徴量を利用してkmeansなどでk個のデータに分割する
- 分割したデータそれぞれに対してSVM分類器を学習し、k個のSVM分類器を生成する
- 分割するとデータが不均衡になりやすいので、データ拡張で均衡になるようにする
- 特徴量選定なども分類器ごとに行う
- 推論時はk個のデータの重心ベクトルと比較し、どのSVM分類器で判定するかを決め、そのSVM分類器で推論する
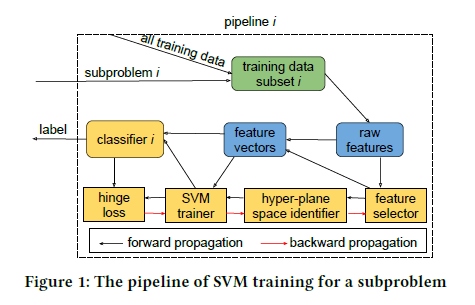
もう少し詳しい説明は scrapbox のほうに書いている。
scrapbox.io
実験
コードも公開されていたので、手元にあるタスクに適用してみた。試したのは去年の言語処理学会に出した扇情的な記事判定タスク。
扇情的な記事判定に向けた定義作成とアノテーション
data.gunosy.io
SVM with Problem Context Aware Pipelineのコードは以下においてある。論文では、Aspects Based Sentiment Analysisという感情分析のタスクを解いている。
- https://github.com/Kurt-Liuhf/absa-svm
- https://github.com/Kurt-Liuhf/absa-svm/blob/master/whole_pipeline.py
whole_pipeline.py ではデータをk分割して、k個のSVMで学習・推論している。論文だとハイパラのチューニングやFeature Selectionもやっているが、whole_pipeline.py ではやっていない。論文のメインはデータ(タスク)を分解してそれぞれに問題を解くところにあるので、whole_pipeline.py でも十分そうな気がしたので今回はこれを使って試した。
結果としては以下のようになって、そこまで性能向上は見られなかった。Task2のほうが難しいタスクというのもあり性能の向上が多少見れた。データと特徴量をNLPの論文のときと少し変えているので、NLPの論文よりベースの性能がやや低い。学習データが1,300件程度しかないため、そもそも分割するほどデータ量がなく、元論文だと10分割しているが、このデータだと3分割が限界だった。元論文でもデータ数が少ないと効果が低いので、もっとデータ量や特徴量を多くするか、もう少しタスク分解が明確なタスクじゃないと効果は低いのかもしれない。
| Task | 判定するラベル | Model | Precision | Recall | F1-score |
| Task1 | SEXUAL, VULGAR | SVM | 0.905 | 0.779 | 0.837 |
| SVM with PCAP | 0.883 | 0.779 | 0.828 | ||
| Task2 | OFFENSIVE, CLICKBAIT | SVM | 0.780 | 0.271 | 0.403 |
| SVM with PCAP | 0.800 | 0.305 | 0.442 |
実験コードを公開してくれているとサクっと試せるのでありがたい。あと、DeepじゃなくてSVMというのもあり、試すのも楽だった。